A BUSZI-2 lekérdező használata
Sass Bálint
v1.0 – 2012. augusztus 10.
A BUSZI-2 lekérdező 12-es vagy újabb Firefox böngészővel használható.
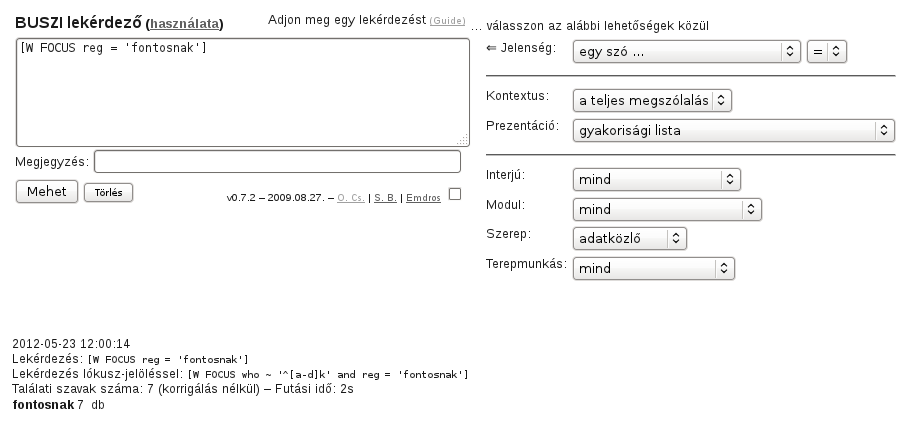
Arra vagyunk kíváncsiak, hogy a fontosnak szóalak hányszor fordul elő a BUSZI-2 korpuszban.
A szűkszavú eredmény arról számol be, hogy a korpuszban hétszer szerepel a kérdezett szó.
A BUSZI-2 lekérdezőfelület felépítését az alábbi ábrán mutatjuk be.
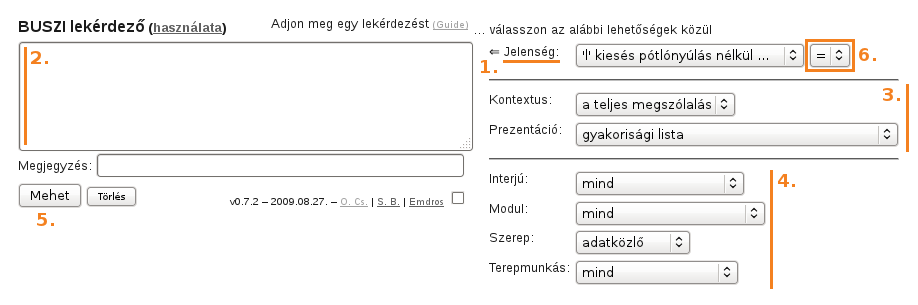
A BUSZI-2 lekérdező használata alapesetben a fenti ábrán található a számoknak megfelelő sorrendben történik. A következő lépésekből áll:
A lekérdezés eredménye a képernyő alső felében jelenik meg.
A BUSZI-2 korpuszban lévő minden bekódolt, lekérdezhető, nyelvészetileg releváns információ a jelenség egységes fogalma alá van besorolva. A Jelenség menüben a következő kategóriákat találjuk:
A BUSZI-2 korpusz alapegysége a szó. A korpusz szavak (illetve szószintű egységek) sorozatának tekinthető. A lekérdezések eredménye – az összes megszólalásra irányuló lekérdezés kivételével – mindig a találati szavak listája.
Alább csak azokat a jelenségeket tárgyaljuk, melyeknél az adott jelenség tulajdonságait egy megjelenő kiegészítő felületen lehet megadni (e jelenségek neve a legördülő menüben három pontra végződik). Az ilyen kiegészítő felület kitöltése után mindig meg kell nyomni a hozzá tartozó OK gombot ahhoz, hogy a kívánt jelenség a lekérdezésmezőbe kerüljön!
Egy szót számos különféle jellemzőjük alapján kereshetjük.
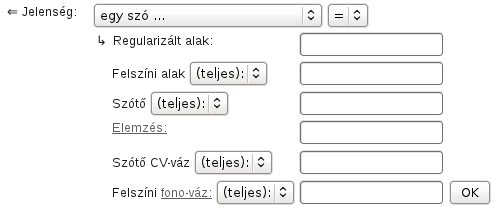
A Regularizált alak az adatközlő által kimondott szó szokásos, kanonikus írott alakja. A Felszíni alak az elhangzott szó hangképéhez legközelebb álló írásos megjelenítés, amit a lejegyzők alkalmaztak. A tát felszíni alakhoz például a tehát regularizált alak tartozik.
A Szótővet és a morfológiai Elemzést a regularizált alak alapján automatikus nyelvi elemzés
határozta meg. A morfológaiai elemzésben a Magyar Nemzeti Szövegtárban is használatos
kódokat használtuk (V – ige, N – főnév, A – melléknév stb.). A kódrendszerről részletesen itt
lehet tájékozódni:
http://corpus.nytud.hu/mnsz/sugo_hun.html#msdrendszer
További kiegészítő jellemző a regularizált Szótő CV-váza, a mássalhangzók jele a C; a magánhangzókat V-vel, illetve képzési hely szerint B (hátulképzett), N (semleges), F (elölképzett) kódokkal is jelölhetjük. Végül megadhatjuk az egy szóra irányuló keresést az elhangzott szóalak fonetikai reprezentációja (Felszíni fono-váz) alapján is. Itt minden hangnak egy egykarakteres jel felel meg. Az egy betűs hangok jele a megfelelő kisbetű, a további jelölések a következők:
| hang(kapcsolat) | cs | dz | gy | ly | ny | sz | ty | zs | dzs | x | qu | ch | y (i-ként) | mgh | mssh |
| jel | F | D | G | J | N | S | T | Z | X | KS | KW | H | I | V | C |
Egy szóra irányuló keresésnél a fenti jellemzőket kombinálni is lehet, megadható például a morfológiai elemzés és a fonetikai váz együttesen.
Ahogy említettük, itt olyan bekódolt nyelvi jelenségeket találunk, melyek egy szóban többször is előfordulhatnak. A különféle hangkiesések tartoznak ide. A vizsgálatok szempontjából az is érdekes lehet, hogy az adott kieső hang a szó mely részén illetve milyen környezetben volt, ezért a felület biztosítja az erre való rákérdezés lehetőségét.
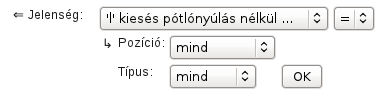
A kiesés Pozíciója lehet szóvégi; szóbelseji kiesés esetén pedig megadhatjuk, hogy magánhangzó/mássalhangzó követte illetve előzte meg az adott kiesést. A kiesés Típusánál elkülöníthetjük azt az esetet, mikor hosszú mássalhangzó esik ki (2 esik ki), valamint mikor a hosszú mássalhangzó rövidül (rövidülés).
A Kontextusnál beállíthatjuk, hogy mekkora szövegkörnyezettel – esetleg az egész megszólalással együtt – kérjük a találati szavakat.
A Prezentációnál kiválaszthatjuk, hogy a találati adatokat milyen formában jelenítse meg a lekérdező. A gyakorisági lista csak a találati szavakból készül, itt a bővebb kontextust figyelmen kívül hagyja a rendszer. Az összesítésben egy táblázatot kapunk kvóták és modulok szerint a találati számokból. Ez a számszerű adatok összevetését könnyíti meg. Rendezett konkordancia esetén az egyes találatok sorra egymás alatt jelennek meg, és a pontos korpuszpozíció megjelölésével, a kért kontextussal, az összes bekódolt jelenség feltüntetésével.
A keresést három független dimenzió szerint szűkíthetjük alkorpuszra. A BUSZI-2 50 interjúja közül bármelyiket külön is vizsgálhatjuk, illetve lehetőség van adott adatközlő-csoport (ún. kvóta: tanárok, egyetemisták, bolti eladók, gyári munkások, szakmunkástanulók) 10 interjújának egyben való vizsgálatára (Interjú). Szűkíthetjük a keresést adott Modulra is, azaz az interjúknak csak azon részeire, ahol bizonyos a terepmunkások által kötelezően érintett témákról esik szó. Végül megadhatjuk, hogy az adatközlő és/vagy a terepmunkás által mondottakra vonatkoztatjuk a lekérdezést (Szerep). Az alapbeállítás itt a terepmunkást kizárja, azaz nem a teljes korpuszra, hanem csak az adatközlők nyelvi produkciójára vonatkozik.
A 2.2. részben említett prezentációs lehetőségek közül csak a konkordancia igényel részletes magyarázatot. Az alábbi ábrán az 1.1. részben említett lekérdezés eredménye látható, de most nem gyakorisági listaként, hanem konkordanciaként.

A fejlécben szerepel a találati szám, majd a találatok következnek szövegkörnyezettel (az ábrán a teljes megszólalással) együtt. Az egyes találatok fejlécében található négy adat pontosan megadja az adott nyelvi adat korpuszbeli pozícióját. Ezek: az interjú azonosítója, a modul azonosítója, a megszólalás interjún belüli sorszáma, valamint, hogy adatközlőtől vagy terepmunkástól származik az adat. A szövegben találati szó félkövérrel van kiemelve. A szavakhoz kapcsolt illetve önálló zöld kódok (pl.: [hesit_length_n] – hezitációs n-nyúlás; [t_drop_final] – szóvégi t-kiesés; [o_hesitation] – hezitáció (ööö); [P] – szünet stb.) a bekódolt nyelvi jelenségeket jelenítik meg (ld. még: 2.1. rész, Jelenség menü). A narancssárga kódok az egyszerre elhangzó beszéd szakaszait jelölik meg.
Az anonimizálás során törölt szavak helyett ### jelenik meg. Fontos megjegyezni, hogy a törölt szavak morfológiai elemzése és az e szavakon lévő annotált jelenségek megőrződnek, így az egyes jelenségek darabszáma az anonimizálás miatt nem változik, a nyelvi adat nem torzul.
A 2.1. részben említettük, hogy a korpusz alapegysége a szó, a lekérdezések adott tulajdonságú szavakat adnak vissza, a lekérdezések eredménye a találati szavak listája. Ezek szerint minden szó csak egy találatot jeleníthet meg. Ez problémát okoz azoknál a jelenségeknél, melyek egy szóban többször is előfordulhatnak (ld. annotációk pozícióval a 2.1. részben), ugyanis nyilván érdekes lehet ezek összesített száma. A megoldást egy korrigáló lépés jelenti, melynek eredményeképpen ilyen esetekben ha egy jelenség egy szóban kétszer/többször szerepel, akkor az adott szó kétszer/többször fog megjelenni a találati listán is. Ilyenkor a fejlécben a Találati szavak száma mellett megjelenik a jelenségek száma is – az ún. jelenségre korrigált érték –, lehetővé téve azt, hogy a felhasználó a számára szükséges értékkel számolhasson.
Ha a B7114 interjú család (CSA) moduljában keressük meg az l-kieséseket, akkor 3 találati szón 4 darab találatot kapunk, mivel a körülbelül szóban két független l-kiesés történt:

Eddig mindvégig egy szóra, illetve az egy szóban lévő valamilyen jelenségre kerestünk rá. Természetes az igény a bonyolultabb, több szóból álló, több szóra kiterjedő lekérdezésekre.
A több egységből álló lekérdezések összeállítását teszi lehetővé a felületen a Jelenség menü mellett látható összeállítás-vezérlő elem (ld.: 1.2. rész, ábra, 6.). Ha ez (alapbeállítás szerint) ’=’-re van állítva, akkor – amint ezt eddig mindig láttuk –, az aktuálisan megadott szó/jelenségre vonatkozó beállítás egészében felülírja a korábbi lekérdezést (a lekérdezésben), azaz ezáltal ugye egy új lekérdezést adhatunk meg. Ha viszont az összeállítás-vezérlőt ’+’-ra állítjuk, akkor kiegészíti a lekérdezésmezőben már korábban meglévő lekérdezés-részletet egy újabbal. Ezen a módon tehát több egységből álló lekérdezéseket tudunk felépíteni.
Olyan több elemű lekérdezés esetén, melyben a megadott elemek nem közvetlenül érintkeznek, hanem közöttük egyéb tetszőleges elem(ek) fordulhat(nak) elő, szükséges a Jelenség menüben található speciális kihagyás lehetőség használata.
Az eddigiekben vagy egy adott szóra, vagy egy adott jelenségre (mely természetesen mindig egy szón jelenik meg) kerestünk rá. Arra is van lehetőség, hogy egy jelenségnek csak egy adott (tulajdonságú) szón való előfordulását keressük. Ehhez először meg kell adnunk a jelenséget (valamilyen annotációt), majd az összeállítás-vezérlőt ’Ť’-re állítva a szót (az egy szó… segítségével). A lekérdezésmezőben a kombinált lekérdezés fog megjelenni, és eredményül a kívánt jelenségnek azon előfordulásait kapjuk, melyekben a kívánt jelenség a kívánt szón fordul elő.
Arra vagyunk kíváncsiak, hogy milyen konfigurációban fordul elő egymást követően egy hezitációs hangzónyúlást tartalmazó hogy szó, és egy önnálló hezitáció (ööö).
A lekérdezést a következőképpen építjük fel:
Ennek eredményeképpen a lekérdezőmezőben a következő lekérdezés áll elő:
Ezt lefuttatva 12 találatot kapunk.